


Während wir uns im ersten Teil der Serie mit den Vorläufern beschäftigt haben, geht es nun im zweiten Teil um die dominierenden computerbasierten Zeichenkodierungen in der zweiten Hälfte des 20. Jahrhunderts.
ASCII, die Basis aller Zeichensätze
»Nach der DNS gehört der ASCII zu den erfolgreichsten Codes auf diesem Planeten.« (Johannes Bergerhausen)
Der 1963 von der amerikanischen Standardbehörde ANSI (American National Standard Institute) verabschiedete ASCII-Kode (gesprochen »Esski«) ist bis heute eine der wichtigsten Zeichenkodierungen. Ziel war es, einen einheitlichen Standard zum Austausch von textbasierten Informationen einzuführen. ASCII steht für US American Standard Code of Information Interchange. Texte konnten damit herstellerunabhängig zwischen Rechnern ausgetauscht und an Ausgabegeräte wie Bildschirme und Drucker gesendet werden. Der ASCII-Zeichenkode ähnelt in seinem Grundprinzip dem Baudot-Kode der Telegrafie. Er ist jedoch ein auf sieben Bit basierender Zeichenkode und bietet somit Platz für 128 Zeichen, von denen 33 Steuerzeichen ausmachen und 95 typografischer Natur sind. Die Tabelle zeigt die Belegung der 128 Positionen des ASCII-Zeichensatzes.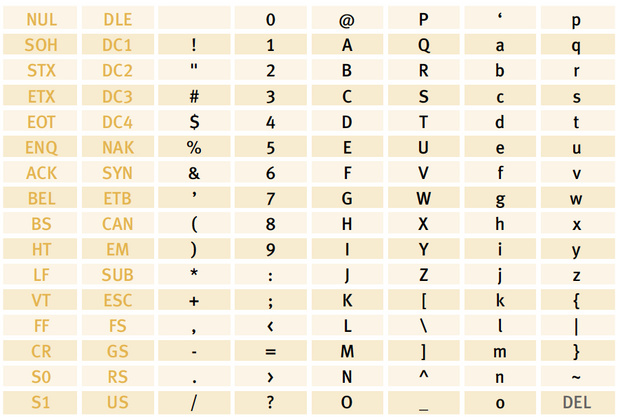
Wie man sieht, vereint ASCII sowohl die Zeichen einer typischen amerikanischen Schreibmaschine als auch Steuerzeichen der Telegrafie. Letztere dienten zum Beispiel dazu, das Ausgabegerät telegrafischer Nachrichten anzuweisen, eine neue Zeile zu beginnen (Line Feed, Zeilenvorschub) und den Druckkopf wieder an den Zeilenanfang zu fahren (Carriage Return, Wagenrücklauf). Heute sind nur noch sehr wenige der Steuerzeichen in Benutzung.

Abbildung: Der Fernschreiber ASR-33 aus den 1960er Jahren war eines der ersten Geräte, das auf den ASCII-Kode setzte.
Vernünftiges Schreiben ist mit dem ASCII-Kode allerdings nur in Englisch möglich, da diakritische Zeichen anderer Sprachen fehlen. Aber auch spätere Zeichenkodierungen setzen allesamt auf dem ASCII-Standard auf. Und dies ist auch der Grund, warum es bei den Zeichen des ASCII-Kodes niemals zu »Sonderzeichensalat« kommt. ASCII ist als Teilmenge in allen Zeichenkodierungen enthalten und diese Zeichen können deshalb (im Gegensatz zu deutschen Umlauten) niemals falsch interpretiert werden.
ASCII-Art
Not macht erfinderisch: Vor der Einführung von grafikfähigen PCs waren die wenigen Zeichen des ASCII-Zeichensatzes die einzige Möglichkeit zur Schaffung von Bildelementen und Illustrationen. Unter Zuhilfenahme von dickengleichen Fonts wie der Courier konnten so einfache Strichgrafiken erstellt werden. In den Signaturen von Newsgroup-Nachrichten und E-Mails finden sich die ASCII-Bildchen teilweise noch heute.
8-Bit-Zeichenkodierungen – Ringen um einen Standard
»Acht Bit? Pro Zeichen? Klasse, dann ist man ja schon nach wenigen Wörtern stockbesoffen.« (aus dem Usenet)
Um auch Zeichen anderer Sprachen kodieren zu können, wurde der ASCII-Kode später auf die bis heute noch üblichen 256 Zeichen erweitert. Diese nunmehr auf 8 Bit ausgelegten Zeichenkodierungen bauen meist auf dem ASCII-Kode auf, enthalten aber an den zusätzlichen Positionen diakritische Zeichen, Umlaute, mathematische Zeichen, Interpunktionen, Währungszeichen und so weiter.
Die Geräte- und Software-Hersteller einigten sich allerdings nicht auf eine einheitliche Belegung der zusätzlichen Zeichen. Die folgende Tabelle zeigt zum Beispiel einen Vergleich der weit verbreiteten Zeichensätze für Windows (CP1252/ANSI) und Mac OS (Mac Roman).
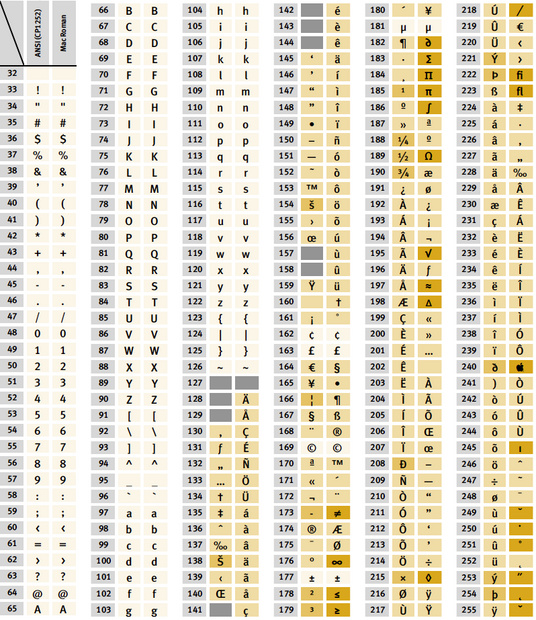
Wie die Darstellung erkennen lässt, ist lediglich der ASCII-Bereich zwischen den Positionen 32 und 126 identisch belegt. Die meisten restlichen Zeichen befinden sich an unterschiedlichen Positionen. Andere oft verwendete Zeichen wie die Bruchzeichen am PC oder die fi- und fl-Ligaturen am Mac sind im jeweils anderen Zeichensatz überhaupt nicht vorhanden. Beim Austausch von Dokumenten zwischen Rechnern, die unterschiedliche Zeichenkodierungen benutzen, muss dies beachtet werden. Wenn zum Beispiel die deutschen Umlaute oder das Eszett durch andere Zeichen ersetzt werden, deutet dies auf einen falschen Zeichenkode hin.

Viele Anwendungsprogramme sind allerdings in der Lage, die Zeichenbelegung selbstständig umzukodieren. So können zum Beispiel Word-Dokumente meist relativ problemlos zwischen PC und Mac ausgetauscht werden. Das Programm kennt die unterschiedliche Belegung der Zeichen und passt diese beim Öffnen des Dokuments automatisch an. Dies gilt freilich nur für die Zeichen, die in beiden Zeichensätzen vorhanden sind – nicht verfügbare Zeichen fehlen oder werden mit dem Symbol not defined markiert – meist ein nicht gefülltes Rechteck.
Damit die Zeichenkodierungen korrekt erkannt und gegebenenfalls konvertiert werden können, muss die Information über die verwendete Kodierung natürlich zunächst erst einmal im Dokument vorhanden sein. Deshalb sollte die Benutzung von Reintextdateien (»TXT«) stets vermieden werden. Denn hierbei kann das Programm die benutzte Kodierung nicht erkennen und greift einfach auf die gerade benutzte Standardkodierung zurück. Dies führt dann nicht selten zum bekannten Sonderzeichensalat, der sicher jedem Computernutzer schon einmal begegnet ist.
Expert-Fonts
Für die für typografische Feinheiten nötigen Zeichen wie besondere Ligaturen, hoch- und tiefgestellte Ziffern, Schwungbuchstaben und so weiter ist in der Standardbelegung eines 8-Bit-Fonts kein Platz mehr. Deshalb war man hier lange auf die so genannten Expert-Fonts angewiesen. Diese verhalten sich wie ein 8-Bit-Font, haben aber an den Positionen der standardisierten Zeichensätze individuelle Zeichen, die sich durch den Formatierungswechsel zum Expert-Font in einen Text einfügen lassen.
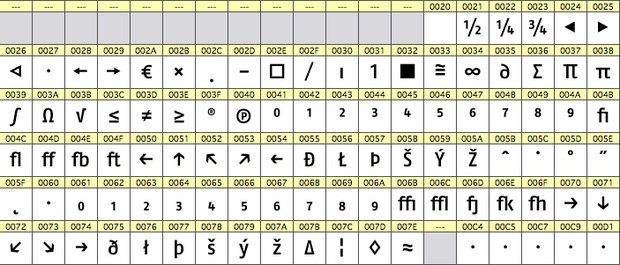
Ein so formatierter Text ist allerdings nur noch mit den vorgesehenen Schriftarten benutzbar. Mit heutigen Unicode-basierten TrueType- und OpenType-Fonts sind diese Notlösungen zum Glück nicht mehr nötig und Expert-Fonts werden immer seltener eingesetzt.
ISO-8859-Zeichenkodierungen
Um den vielen voneinander abweichenden Zeichenkodierungen entgegenzuwirken, entwickelte die Internationale Organisation für Normen (ISO) bereits in den 1980er Jahren eine Serie von ISO-8859-Standards. Diese definieren 15 Normen von 8-Bit-Zeichenkodierungen:
- ISO 8859-1 (Latin-1) - Westeuropäisch
- ISO 8859-2 (Latin-2) - Osteuropäisch
- ISO 8859-3 (Latin-3) - Südeuropäisch und Esperanto
- ISO 8859-4 (Latin-4) - Baltisch
- ISO 8859-5 (Kyrillisch)
- ISO 8859-6 (Arabisch)
- ISO 8859-7 (Griechisch)
- ISO 8859-8 (Hebräisch)
- ISO 8859-9 (Latin-5) - Türkisch statt Isländisch, sonst wie Latin-1
- ISO 8859-10 (Latin-6) - Nordisch
- ISO 8859-11 (Thai)
- ISO 8859-13 (Latin-7) - Baltisch (ersetzt Latin-4 und -6)
- ISO 8859-14 (Latin-8) - Keltisch
- ISO 8859-15 (Latin-9) - Westeuropäisch mit Eurozeichen
- ISO 8859-16 (Latin-10) - Südosteuropäisch mit Eurozeichen
Die Zeichenkodierung ISO-8859-1, auch bekannt als ISO Latin 1, ist der dominierende Standard in Westeuropa, den USA, Australien und großen Teilen Afrikas. Diese Zeichenkodierungen waren und sind insbesondere bei der Kommunikation über das Internet im Einsatz, um Inhalte plattformunabhängig austauschen zu können. Innerhalb vom Webseiten wird die zu verwendende Zeichenkodierung versteckt übertragen und der Browser dadurch angewiesen, die Standard-Zeichenkodierung gegebenenfalls zu wechseln:
meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"
Fehlt diese Angabe, werden Texte unter Umständen falsch interpretiert, zum Beispiel, wenn eine deutschsprachige Webseite mit Umlauten und Eszett in Osteuropa abgerufen wird.
Die 8-Bit-Zeichenkodierungen werden zunehmend vom Unicode-Standard verdrängt. Dazu mehr im letzten Teil der Serie.
Bildnachweise:
- 1. Bild, Rechenzentrum Aachen, Deutsches Bundesarchiv, B 145 Bild-F031434-0011, Quelle
- Bild: ASR-33, Quelle: Wikipedia Commons. Nutzer: AlisonW





{kind=link}
{kind=link}